How ISVs and startups scale on DigitalOcean Kubernetes: Best Practices Part II - Observability
Introduction
At DigitalOcean, our mission is simple: provide the tools and infrastructure needed to scale exponentially and accelerate successful cloud journeys. Many Independent Software Vendors (ISVs) and startups including Snipitz, ScraperAPI, Nitropack, Zing, and BrightData have experienced successful scaling and rapid growth on DigitalOcean Kubernetes.
DigitalOcean Kubernetes stands out as a managed Kubernetes platform due to its simplified user experience, fixed and predictable pricing model, ample egress data transfer, and versatile range of virtual machines. These features make it an attractive choice for businesses seeking a reliable and cost-effective solution to deploy and scale their applications on Kubernetes.
In Part 1 of the series, we covered the challenges in adopting and scaling on Kubernetes, as well as “Developer Productivity” best practices. As businesses grow and their applications become more complex, observability becomes a critical component of their production environment. Observability helps identify issues, resolve them promptly, and optimize the environment for better performance and resource utilization.
In this current segment (Part 2), we focus on observability best practices for DigitalOcean Kubernetes. We will first look at the big picture of observability, discussing its various components and their importance. Then, we will explore the common challenges faced by businesses when implementing observability in a Kubernetes environment. Finally, we will provide a comprehensive checklist of best practices to help you achieve effective observability for your applications running on DigitalOcean Kubernetes.
Observability - The Big Picture
Observability and monitoring are often used synonymously, but they differ in their approach and scope. Monitoring focuses on tracking predefined metrics and triggering alerts when thresholds are breached, while observability provides a holistic view of your system’s state by combining metrics, logs, events, and traces. Observability in a Kubernetes environment encompasses various components that work together to provide visibility into the health and performance of your applications and infrastructure. Observability enables you to gain deeper insights and diagnose issues more effectively. Traditionally, observability relies on three pillars: metrics, logs, and traces. However, in the context of Kubernetes deployments, events play a significant role in troubleshooting and gaining insights into your cluster’s health. Therefore, we will explore these four pillars of Kubernetes observability as shown below.
.png)
- Metrics: Metrics are numerical representations of data measured over intervals of time. In a Kubernetes environment, metrics can include CPU and memory utilization, network traffic, disk I/O, and custom application-level metrics. Metrics are essential for monitoring resource usage, identifying performance bottlenecks, and setting up alerts. A typical metric example in Prometheus is below:
container_cpu_usage_seconds_total{container_name="oauth-server", namespace="production"}[5m]This metric measures the total CPU time consumed by the oauth-server container in the production namespace over the last 5 minutes.
- Logs: Logs are streams of event records that capture information about the state and activities of your applications and infrastructure. Kubernetes components, such as the control plane and worker nodes, generate logs, as do your containerized applications. Logs are invaluable for debugging, auditing, and troubleshooting issues. A typical log entry in Kubernetes is below:
2024-03-14T10:00:00Z ERROR [oauth-server] Failed to connect to database: timeout exceeded.This metric measures the total CPU time consumed by the oauth-server container in the production namespace over the last 5 minutes.
- Events: Kubernetes generates events to record the state changes and significant occurrences within the cluster. Events can provide insights into resource creation, deletion, scaling, and error conditions. Monitoring events can help you understand the overall health of your Kubernetes cluster and respond promptly to critical situations. A typical event in Kubernetes is below:
2024-03-14T10:05:00Z INFO [kubelet] Successfully pulled image "myapp:latest" for pod "myapp-pod" in namespace "production".This log shows kubelet's success in pulling the latest image for "myapp-pod" in the "production" namespace.
- Traces: In a distributed microservices environment, traces provide end-to-end visibility into individual requests as they propagate through different services. Traces help identify performance bottlenecks, latency issues, and error conditions across service boundaries, making them essential for troubleshooting and optimizing complex applications. Here is a typical trace example:
Trace ID: 12345. Operation: GET /api/v1/users. Duration: 250ms. Status: Success.This trace captures a successful GET request to the /api/v1/users endpoint, taking 250 milliseconds to complete.
- Alerts: Effective observability relies heavily on alerting mechanisms. By setting up alerts based on predefined thresholds or conditions, you can promptly notify the relevant teams or individuals when issues arise, enabling faster response times and minimizing the impact on your applications and customers. Here is an alert example:
Alert: CPU utilization for pod "api-server" in namespace "production" exceeds 80% for more than 5 minutes.This alert notifies that the CPU utilization of the "api-server" pod has been above 80% for over 5 minutes, potentially indicating an issue.
Observability spans across multiple layers:
-
The underlying platform (Kubernetes control plane, worker nodes, networking, and storage)
-
Your applications (microservices, containers, and workloads)
-
Business data (application logs, user interactions, and domain-specific metrics).
By capturing and correlating data from the above layers, you can gain a comprehensive understanding of your system’s behavior and detect issues more effectively.
Another crucial aspect to consider is whether you operate a single cluster or multiple clusters. In a multi-cluster environment, observability becomes even more critical as you need to aggregate and correlate data across different clusters, potentially spanning multiple regions or cloud providers.
For an ISV or startup, it’s essential to strike a balance between the observability data you collect and the insights you need. Developers may require more granular data for debugging and optimizing specific components, while operators and site reliability engineers (SREs) may focus on higher-level metrics and events that provide a comprehensive view of the overall system’s health.
With this big picture in mind, let us review an example of how to use the observability data to troubleshoot issues, find root cause, and take actions.
Finding needle in the haystack - An example
Imagine you’re running a popular e-commerce application on Kubernetes, and during a peak sales period, you start receiving complaints from customers about slow response times and intermittent errors when adding items to their shopping carts. How do you go about identifying the root cause of this issue and resolving it?
Let’s walk through this hypothetical scenario:
-
Metrics reveal performance degradation: Your monitoring dashboard shows a spike in the 95th percentile response times for the shopping cart microservice, indicating potential performance issues. Additionally, you notice increased CPU and memory utilization on the nodes running this service.
-
Logs provide context: By analyzing the application logs, you discover that the shopping cart service is logging frequent errors related to database connection timeouts. This could potentially explain the performance degradation and intermittent errors experienced by customers.
-
Traces highlight latency: You turn to distributed tracing and notice that requests to the shopping cart service are taking significantly longer than usual, with most of the latency occurring during the database interaction phase.
-
Events point to resource contention: Reviewing the Kubernetes events, you find that several nodes in the cluster have been experiencing high memory pressure, leading to frequent kernel OOM (Out-of-Memory) events and pod evictions.
-
Correlation and root cause identification: By correlating the information from metrics, logs, traces, and events, you can piece together the root cause; the increased traffic during the peak sales period has led to resource contention on the nodes hosting the shopping cart service and its database. This resource contention has caused database connection timeouts, resulting in slow response times and intermittent errors for customers.
With this insight, you can take immediate action to resolve the issue, such as scaling out the shopping cart service and its database. Additionally, you can set up appropriate alerts and notifications to detect similar issues proactively in the future.
This example demonstrates the power of observability in quickly identifying and diagnosing issues within complex distributed systems. By leveraging metrics, logs, traces, and events, and correlating data from these sources, you can gain deep visibility into your application’s behavior and pinpoint the root cause of performance problems or failures, ultimately enabling faster resolution and better user experiences.
The challenges of Kubernetes observability
Implementing effective observability in a Kubernetes environment can present several challenges, especially for startups and ISVs with limited resources. Here are some common challenges and considerations:
-
Data volume and signal-to-noise ratio: Kubernetes environments can generate a vast amount of observability data, including metrics, logs, traces, and events. Sifting through this deluge of data to identify relevant signals and actionable insights can be overwhelming and is not a good use of time.
-
Storage costs: Storing and retaining observability data for extended periods may not be justified unless needed for security or compliance reasons. Finding the right balance between data retention policies and storage costs is crucial to ensure optimal cost-efficiency while maintaining necessary historical data for analysis and compliance.
-
Data correlation and context: Observability data from different sources (metrics, logs, traces, events) can be siloed, making it challenging to correlate and derive meaningful insights. Proper dashboards and alerts are key to getting good insights.
-
Alerting and notification management: Defining appropriate alerting rules and managing notifications effectively can be a challenge.
-
Scaling and multi-cluster observability: As businesses grow and their Kubernetes footprint expands across multiple clusters or regions, observability becomes increasingly complex. Aggregating and correlating observability data from multiple sources while maintaining visibility and control can be a significant challenge for ISVs with limited resources.
-
Security and compliance: Observability data can contain sensitive information, such as application logs or user-related data. ISVs must ensure proper access controls, data encryption, and compliance with industry regulations and standards, which can add complexity and overhead to their observability implementations.
To address these challenges effectively, ISVs should consider adopting observability best practices tailored to their specific needs and constraints as discussed in the following section.
Best practices in Kubernetes observability
Implementing effective observability in a Kubernetes environment requires a structured approach and adherence to best practices. Here’s a checklist of key recommendations.
Checklist: Treat observability as a journey
Observability is an ongoing process; it is not a one-time implementation cost. Your observability needs will change as your Kubernetes environment evolves. Embrace an iterative approach, and continuously refine and optimize your observability practices to adapt to new requirements, emerging technologies, and changing workloads.
Before embarking on your observability journey, define clear goals and objectives. These goals can be simple and focused, such as:
-
Enhancing visibility into the system and applications
-
Improving Mean Time to Detection (MTTD) for issues
-
Reducing Mean Time to Resolution (MTTR) for incidents
Metrics are an absolute necessity for any observability strategy. Begin your observability journey with metrics; they provide a foundation for understanding system behavior and performance.
Gradually incorporate logs and events into your observability stack as you mature along your observability journey. Logs provide detailed information about application behavior and can help in troubleshooting and root cause analysis. Events offer insights into the state changes and significant occurrences within your Kubernetes cluster.
It’s generally not recommended for ISVs at SMB scale to start with distributed tracing unless you have a clear understanding of its complexities and benefits.
Checklist: Consider a SaaS platform for observability
Leveraging a SaaS observability platform is a best practice for ISVs and startups with limited resources because it allows them to focus on their core business objectives while benefiting from enterprise-grade observability capabilities. By outsourcing the observability infrastructure to a managed service provider, teams can reduce operational overhead, minimize the need for specialized expertise, and ensure scalability and reliability of their observability stack.
SaaS observability platforms offer a wide range of features and benefits, including:
-
Centralized data collection for metrics, logs and events.
-
Scalability and reliability by handling large volumes of observability data without the need to manage the underlying infrastructure.
-
Pre-built integrations with popular Kubernetes distributions, monitoring tools, and logging frameworks.
-
Powerful querying and visualization with pre-built dashboards.
-
Alerting and notifications.
-
Collaboration and sharing among team members by sharing dashboards, alerts, and insights.
Most ISVs and startups have limited resources and need to focus on core business. Leveraging Software-as-a-Service (SaaS) observability solutions is a good option. Managed services like Logtail, Papertrail, Datadog, New Relic, Elastic Cloud, or Grafana Cloud can provide a comprehensive observability platform with minimal operational overhead, allowing you to focus on core business objectives while benefiting from scalable, enterprise-grade observability. When evaluating SaaS observability platforms, consider factors such as pricing, ease of use, integrations with your existing tools and platforms, and customer support.
Checklist: Consider kube-prometheus-stack for self-hosting
Using the kube-prometheus-stack is a best practice for self-hosted observability because it provides a battle-tested and integrated solution tailored specifically for Kubernetes environments. By leveraging this stack, teams can quickly set up a robust monitoring and alerting system without the need for extensive configuration and integration efforts. The stack follows best practices and provides a solid foundation for Kubernetes observability.
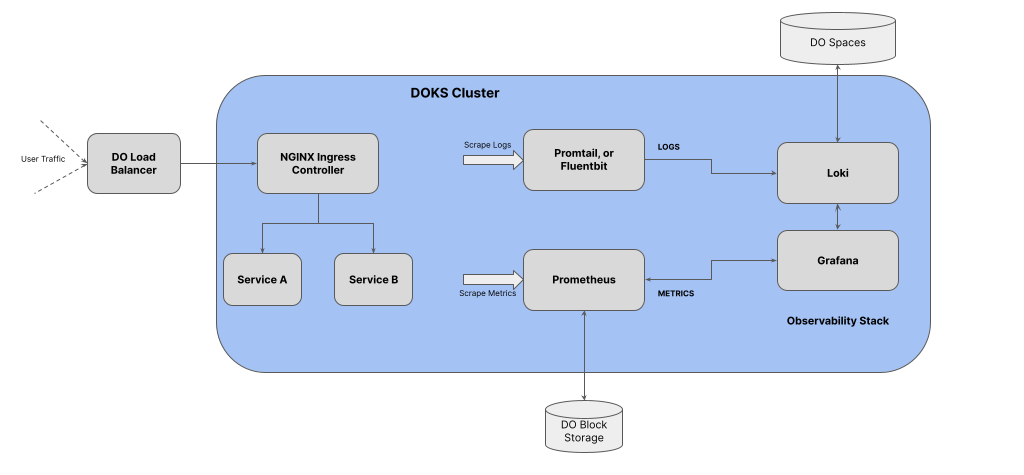
The kube-prometheus-stack is a collection of Kubernetes manifests, Grafana dashboards, and Prometheus rules that provide a comprehensive and easy-to-deploy monitoring and alerting stack. The stack includes popular open-source tools such as Prometheus, Grafana, and Alertmanager with best-practices alerts, preconfigured to work seamlessly with Kubernetes. The stack can be extended to monitor and analyze Kubernetes events and logs, providing valuable insights into cluster state and resource changes. We recommend the Kubernetes starter kit (chapter 4 - Observability) tutorial for customizing your installation, including data management.
We recommend Loki for logs with Grafana. Loki is a scalable and highly available, multi-tenant log aggregation system by Grafana Labs focusing on simplicity and efficiency. It aims to provide a cost-effective solution for storing and querying large volumes of log data (in S3/Spaces store). Unlike traditional log aggregation systems that index the contents of the logs, Loki allows users to search logs using labels rather than requiring full-text search. This design choice significantly reduces the storage and computational requirements. Loki integrates seamlessly with Grafana, enabling rich querying and visualization capabilities.
To further enhance the alerting capabilities of the kube-prometheus-stack, consider integrating tools like Robusta. Robusta can enrich alerts from Alertmanager and Kubernetes events, providing additional context and streamlining alert management. It helps in identifying and responding to issues proactively.
When using Grafana dashboards, it’s recommended to tailor them to cater to different user personas. Developers may require more granular information for debugging and optimization, while operators and SREs might benefit from higher-level views of system health and performance. Customizing dashboards based on user roles improves productivity and provides actionable insights.
Checklist: Keep your costs under control
Keeping observability costs under control involves implementing strategies to manage and optimize the storage and retention of observability data. As Kubernetes environments grow and generate increasing amounts of metrics, logs, and events, the storage requirements for this data can quickly escalate, leading to substantial costs if not properly managed.
To understand the importance of cost control, let’s consider an example of a 10-node Kubernetes cluster. Suppose each node generates an average of 100 MB of log data per day and 100 metrics per minute. In this scenario, the daily storage requirements would be:
Log data: 10 nodes × 100 MB/day = 1 GB/day
Metrics data: 10 nodes × 100 metrics/minute × 1440 minutes/day × 8 bytes/metric = 115 MB/day
This would be approximately 30 GB for logs and 3.45 GB for metrics, per month. These can quickly add up, adding to your costs.
To keep costs under control, consider the following strategies:
-
Data collection optimization: Select the metrics, logs, and events that are critical for your observability needs. Leverage filtering and aggregation techniques to reduce data volume before storage.
-
Data retention policies: Define clear data retention policies based on your observability requirements and compliance needs. Implement tiered retention policies, storing high-resolution data for a shorter period and aggregated data for longer durations.
Checklist: Centralize observability for multi-cluster environments
Many ISVs operate multiple Kubernetes clusters. While you can still manage with standalone deployments of kube-prometheus-stack and good alerting (eg. slack integration), centralizing observability becomes a best practice in these situations.
Centralizing observability provides the following benefits.
-
Unified visibility: By aggregating observability data from multiple clusters, you can obtain a single pane of glass view of your entire Kubernetes environment.
-
Simplified troubleshooting: Centralized observability allows you to quickly identify and investigate issues that span across multiple clusters.
-
Consistent monitoring and alerting: With a centralized observability solution, you can define and enforce consistent monitoring and alerting policies across all your clusters.
-
Efficient resource utilization: Centralizing observability helps you optimize resource utilization by providing insights into the performance and scalability of your applications across clusters.
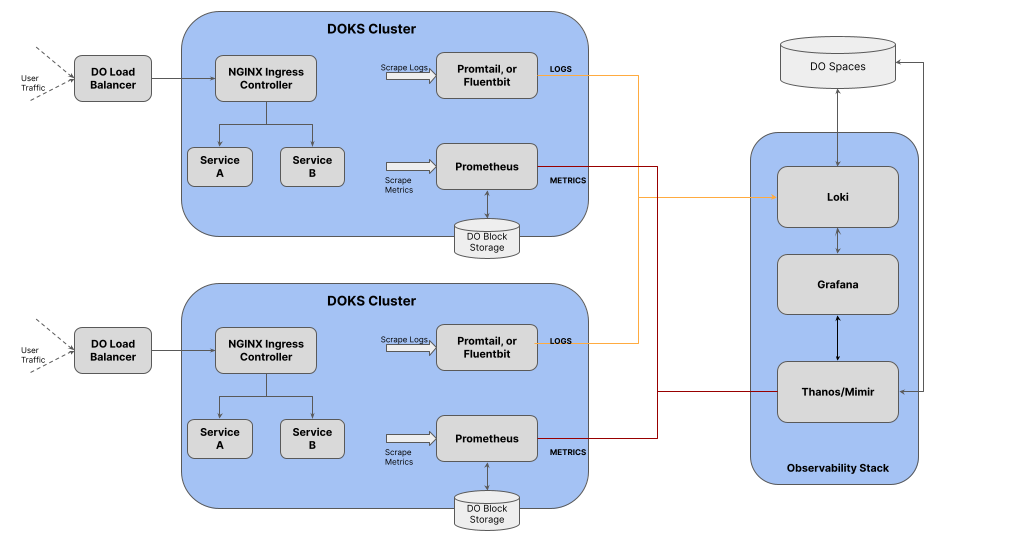
The above diagram depicts such an architecture. To centralize observability in a multi-cluster environment, you can leverage tools like Grafana Mimir or Thanos. These tools are designed to aggregate and federate observability data from multiple Prometheus instances, which are commonly used for monitoring Kubernetes clusters.
Grafana Mimir is a highly scalable and distributed time-series database that can ingest and store metrics from multiple Prometheus servers. You just need to connect Mimir as a data source to Grafana. It saves a lot of configurations, also you do not have to expose every prometheus service on each cluster. Now you can have a global query view across all connected clusters, enabling you to perform cross-cluster analysis and visualization. Mimir also offers features like horizontal scalability, high availability, and long-term storage capabilities.
When centralizing observability, consider the following aspects:
-
Data aggregation: Determine the metrics, and logs that need to be aggregated from each cluster and configure your observability tools accordingly.
-
Query performance: Ensure that your centralized observability solution can handle the query load and provide fast response times, even when dealing with large volumes of data from multiple clusters.
-
Data retention: Define data retention policies for your centralized observability system, taking into account the storage requirements and the need for historical data analysis.
-
Access control: Implement proper access control mechanisms to ensure that users can only access and view observability data relevant to their roles and responsibilities.
Observability is an ongoing journey; continuous improvement and adaptation are key to success. Regularly review and refine your observability practices to align with evolving business needs and technological advancements.
Next steps
As we continue to explore the ISV journey of Kubernetes adoption, our ongoing blog series will delve deeper into the resilience, efficiency, and security of your deployments.
-
Developer Productivity (Part 1): Maximize developer productivity by streamlining the development and deployment process in Kubernetes environments.
-
Observability (this post): Unpack the tools and strategies for gaining insights into your applications and infrastructure, ensuring you can monitor performance and troubleshoot issues effectively.
-
Reliability and scale (Part 3): Explore how to manage zero-downtime deployments, readiness/liveness probes, application scaling, DNS, and CNI to maintain optimal performance under varying loads.
-
Disaster preparedness (Part 4): Discuss the importance of having a solid disaster recovery plan, including backup strategies, practices and regular drills to ensure business continuity.
-
Security (Part 5): Delve into securing your Kubernetes environment, covering best practices for network policies, access controls, and securing application workloads.
Each of these topics is crucial for navigating the complexities of Kubernetes, enhancing your infrastructure’s resilience, scalability, and security. Stay tuned for insights to help empower your Kubernetes journey.
Ready to embark on a transformative journey and get the most from Kubernetes on DigitalOcean? Sign up for DigitalOcean Kubernetes start here.
If you’d like to see DigitalOcean Kubernetes in action, join this OnDemand webinar to watch a demo and learn more about how DigitalOcean’s managed Kubernetes service helps simplify adoption and management of your Kubernetes environment.
Related Articles

Top 10 Reasons to Choose DigitalOcean’s Managed Kafka Solution
Faye Hutsell
- April 23, 2024
- 4 min read

Accelerate Your Business with DigitalOcean App Platform
- April 1, 2024
- 5 min read

Access the New Cloud Buying Criteria Proposed by IDC for 2024
Faye Hutsell
- March 27, 2024
- 3 min read