How SMBs and startups scale on DigitalOcean Kubernetes: Best Practices Part III - Reliability
Introduction
This article is part of a 6-part series on DigitalOcean Kubernetes best practices targeted at SMBs and startups. In Part 1 of the series we covered the challenges in adopting and scaling on Kubernetes, as well as “Developer Productivity” best practices, and in Part 2 of the series we covered “observability” best practices, including the importance of monitoring, logging, and tracing in a Kubernetes environment.
In this current segment (Part 3), we focus on reliability. The meaning and scope of reliability can be different for a small and medium-sized business (SMB) compared to an enterprise. SMBs often have limited resources and smaller-scale deployments, which present unique challenges in ensuring the reliability of their Kubernetes clusters. We start with a broad overview of the challenges. Then we provide a set of checklists and best practices that SMBs can follow to help ensure reliability in their Kubernetes environments. Our focus is primarily on SMB-scale clusters, typically consisting of fewer than 500 nodes.
Reliability Challenges
Reliability refers to an application’s ability to work as expected in different situations. When things do not work as intended, the problems manifest in various forms, for example:
- Functionality: The application simply does not work. Common issues include:
- Pod crash-looping: Pods continuously restart due to application crashes or configuration issues.
- Incorrect load balancer/ingress configuration: Misconfigured load balancers or ingress controllers prevent traffic from reaching the application.
- Certificate not renewed: Expired SSL/TLS certificates cause connection failures.
- Incorrect resource limits or requests: Improper resource allocation leads to pod eviction or resource starvation.
- Missing or misconfigured dependencies: Incomplete or incorrect configuration of application dependencies (databases, message queues, etc.) prevents the application from functioning correctly.
- Latency: While the application may work fine for the most part, a percentage of requests may experience slow response times. Latency issues can arise from various factors:
- Network congestion: Insufficient network bandwidth or network bottlenecks lead to increased latency.
- Compute resource limitations: Inadequate CPU or memory allocation for the application results in slower processing times.
- Database performance: Slow database queries or insufficient database resources cause delays in data retrieval.
- External dependencies: Latency in external services or APIs that the application relies on can impact overall response times.
To address these challenges, it is crucial to adhere to well-established practices in Kubernetes and cloud-native computing while considering the specific requirements and characteristics of your application.
Reliability Best Practices
Implementing effective reliability in a Kubernetes environment requires a structured approach and adherence to best practices. Here’s a checklist of key recommendations.
Checklist: Right-size your nodes
- Understand Your Application Requirements
Understanding the specific demands of your application is crucial. This involves determining whether your application primarily requires high computational power (compute-bound), significant memory (memory-bound), or intensive data transfer (I/O-bound). Once the type of application is identified, accurately assess the needed CPU, RAM, and storage to ensure that the nodes are neither over-provisioned nor under-provisioned.
It is common to encounter challenges such as underutilized compute resources, which can happen when a compute-heavy application does not fully utilize the CPU capabilities while maxing out memory. Another challenge is the inability to schedule new pods on nodes that are 60% utilized but lack sufficient free resources to meet new pod requirements. Additionally, imbalances in resource utilization across nodes can lead to inefficiencies, where some nodes may be CPU-heavy and under-utilize memory and vice versa.
- Choose the Right Node Size and Type
Choosing the correct node size involves selecting nodes that fit the resource profile of your application closely. Oversizing can lead to wasted resources and unnecessary costs, whereas undersizing might hinder performance. For better scalability and flexibility, smaller nodes can be beneficial, allowing more granular scaling and resource allocation that can adapt more fluidly to changing demands. However, in certain scenarios, such as running large, monolithic applications or workloads with high memory requirements, choosing larger nodes can be advantageous. Larger nodes can provide increased performance, reduce fragmentation and the overhead of inter-node communication. The choice of node type should be tailored to the application’s requirements: shared nodes are generally adequate for development/staging resources; dedicated nodes suit applications that are resource-intensive or require low latency; compute-optimized nodes are ideal for CPU-intensive tasks; and memory-optimized nodes should be used for applications that consume large amounts of memory. Here are some guidelines for right sizing nodes for your application.
- Use Node Pools and Leverage Scheduling Features
Node pools allow for the grouping of nodes that serve similar types of applications or workloads, facilitating better resource management and allocation efficiency. By grouping applications that share similar resource needs into the same node pool, you can enhance both performance and resource utilization, making it easier to manage and scale applications dynamically.
Kubernetes scheduling features such as pod affinity and anti-affinity can significantly improve the efficiency of resource utilization. Pod affinity rules help in placing related pods close to each other to reduce latency, while anti-affinity rules prevent resource contention by avoiding placing too many similar resource-demanding pods on the same node.
Checklist: Right-size your pods
It is important when deploying resources inside your Kubernetes cluster that you indicate how much CPU and memory RAM you want to allocate to your deployed resources. By describing those constraints, you are helping the kube-scheduler control plane component make better bin packing decisions when assigning your pods to your worker nodes. Once your pods are assigned on worker nodes, the kubelet component will then ensure that the request and limits specified on the pod’s containers are enforced.
For both the CPU and RAM requests, the container runtime will guarantee the specified resource values. Thus, you need to ensure that your biggest worker node pool contains worker nodes that can accommodate for the specified CPU or RAM request, or else you could end up in a situation where your pods can’t be scheduled on any worker nodes and could result in downtime for your application. Also, since the request value will guarantee the reservation of those resources, it is important that you are not over-requesting resources and pay for extra resources that you don’t need or could be used for other workloads.
Next, is the CPU and Memory (RAM) limits. Kubernetes will enforce those limits and prevent deployed resources from using more than what they are given. This is important to understand but CPU and RAM limits behave differently. When a CPU limit is reached, your pod containers will be throttled. This throttling could lead to degraded performance of your applications especially if they are running against those CPU limits values for a prolonged period of time. This could be a good opportunity to revisit your pod container limit value when an issue like that occurs and give enough CPU to your workloads. That said, even if that throttling could lead to degraded performance, the containers won’t be terminated or evicted by the container runtime since the CPU is a compressible resource. Your application can remain accessible but the performance will likely be altered. Be careful when setting limits. By omitting CPU limits, processes will be able to use any additional CPU capacity available on the node. When CPU limits are set, applications may be CPU throttled even when the node has otherwise idle CPU capacity. As a general rule of thumb, we recommend that your application omits the CPU limits entirely unless you have strict needs that implies setting them.
On the other hand, when the pod memory consumption limit is reached, if the container allocates more memory than it is allowed to, the container will become a candidate for termination. You will see a status of OOM (Out Of Memory) on the pod status when that termination occurs. This behavior is important since terminated pods could cause downtime for your applications. Even if your pods are controlled by a ReplicaSet or part of a Deployment, until the new pods are scheduled and back in a running state, your customers could be affected by OOM terminated events.
Checklist: Assign quality of service to pods
Kubernetes offers three Quality of Service (QoS) classes. Those QoS classes are used by Kubernetes when there are no more available resources on a given node and you need to make a decision regarding which pod needs to be evicted. The QoS class assigned to the pod will determine the eviction priority. There are three choices of QoS classes that are assigned to a pod on creation: BestEffort, Burstable and Guaranteed. When an eviction decision needs to be made, the pods with a BestEffort QoS will be terminated first, followed by Burstable and lastly Guaranteed. Here are the criteria that dictate which category a pod will fall into:
-
Burstable
-
The Pod does not meet the criteria for QoS class Guaranteed.
-
At least one Container in the Pod has a memory or CPU request or limit.
-
Guaranteed
-
Every Container in the Pod must have a memory limit and a memory request.
-
For every Container in the Pod, the memory limit must equal the memory request.
-
Every Container in the Pod must have a CPU limit and a CPU request.
-
For every Container in the Pod, the CPU limit must equal the CPU request.
-
BestEffort
-
Does not meet the criteria of Burstable or Guaranteed
That said, it is important to consider the right CPU request and limit to fall into the right QoS class based on your application needs. For example, for critical applications, you will want them to have a QoS of Guaranteed so they are prioritized during scheduling by the kube-scheduler and evicted last if nodes are running out of resources.
To optimize CPU and memory allocations in Kubernetes, you have several options:
-
Use the Vertical Pod Autoscaler (VPA) with the Metrics Server. The Metrics Server collects real-time resource usage data, which VPA analyzes to provide recommendations on CPU and memory limits based on historical usage patterns.
-
Leverage Fairwinds Goldilocks, which is built on top of VPA and offers a user-friendly interface for resource recommendations.
-
Use Robusta Kubernetes Resource Recommender (KRR), a lightweight approach that utilizes Prometheus and cAdvisor to generate resource recommendations. It does not require any agent, and you can simply run a CLI tool on your local machine for immediate results.
Each of these tools offers a unique approach to resource optimization, allowing you to choose the one that best fits your cluster’s needs and existing infrastructure.
Checklist: Use Probes for Health Checks
Kubernetes container probes are a key concept for ensuring the reliability of our applications. In this next section, we’ll discuss in more detail the different types of probes, when to use them, how to use them, and their key role they have in the reliability of our system. First, the definition of a probe is to search into and explore very thoroughly. You can either use the HTTP protocol and make a request against our application, execute a shell command, try to open a TCP socket to our container on a specified port, or perform a gRPC health check. Any of those mechanisms can be used to interact with our application and determine its health. Let’s review the three different use cases for Kubernetes probes.
The first probe we’ll cover is the Startup probe, this probe is useful when you have applications that have a slow startup. This probe is used to know when the application has started. This will also block the liveness probe and the readiness probe from running until the startup probe succeeded. You can define the startup probe in the container spec with looser values and usually higher failure thresholds and delays than the readiness probe or liveness probe since the latter need to detect problems with a quicker response time.
The second probe is the Readiness probe. This probe indicates if the container is ready to accept and serve traffic. Usually, applications will have some tasks to do when they initialize or during their runtime. For example, they might pull secrets from an external vault, load their cache, interact with different services and do other tasks which should prevent them from receiving traffic. That said, you don’t want to send traffic to those pods/containers until they are fully ready to accept and serve the traffic. If those pods are targeted by a Kubernetes service and they are reporting that they are not in a Ready state, they won’t receive traffic. Omitting the readiness probe on a pod container definition backing a Kubernetes service, by default, will consider the container as Ready and will immediately be considered for receiving traffic. This is a scenario to be avoided since it could result in errors in your system for a brief period of time until the container finishes its bootstrapping.
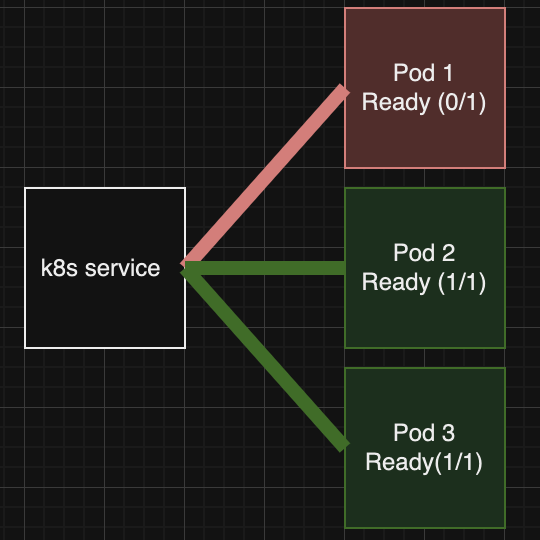
The last probe we’ll cover is the Liveness probe. Once your application is running smoothly, we still want to ensure that it stays that way and if any potential issues are detected that are unrecoverable and would require a pod restart, you can use the liveness probe for that. This probe will periodically check our application health and if the check fails, it will terminate the pod. A typical use case for liveness probes is for a temporary mutation of a detectable condition that can be handled via a restart (e.g. memory corruption, a memory leak, deadlocks) until the root cause of the problem can be found. You want to ensure that the readiness probe fails first, turning the pod in a NotReady state which causes the traffic to stop going to that pod but keeping the possibility of the pod returning back in a Ready state. Then, if the failure is maintained for a prolonged period of time, it seems like you are in an unrecoverable state in which it would make sense for the liveness probe to fail and trigger a pod restart.
Finally, something that you should be aware of is that probes should not have external dependencies. The last thing you want to introduce in our cluster are cascading events that could cause many applications to have their probes fail which could lead to unresponsiveness or a lot of pod restarts. Thus, we recommend that probes logic does not interact with external components, APIs, third party services etc. where one failure could cause many applications to fail.
Checklist: Deployment strategies
In this section, we’ll go over two deployment rollout strategies that you can introduce in your continuous delivery pipeline to make your system more reliable when introducing changes to your production system. We’ll also assume that you have correctly instrumented your applications with metrics and you are able to track the four golden signals (Latency, Traffic, Errors, Saturation).
The first deployment strategy we’ll cover is the canary deployment. A canary deployment rolls out a small set of replicas with the new release and monitors the behavior with production traffic. If the new rollout is behaving correctly, you can increase the number of replicas using the new version. If it is the opposite, you can quickly revert those replicas, and gather some useful information on the failure domains from the logs and metrics. If an issue was detected on the canary deployment, you can be assured that it only affected a small percentage of the production traffic. In the Kubernetes context, consider the following setup.
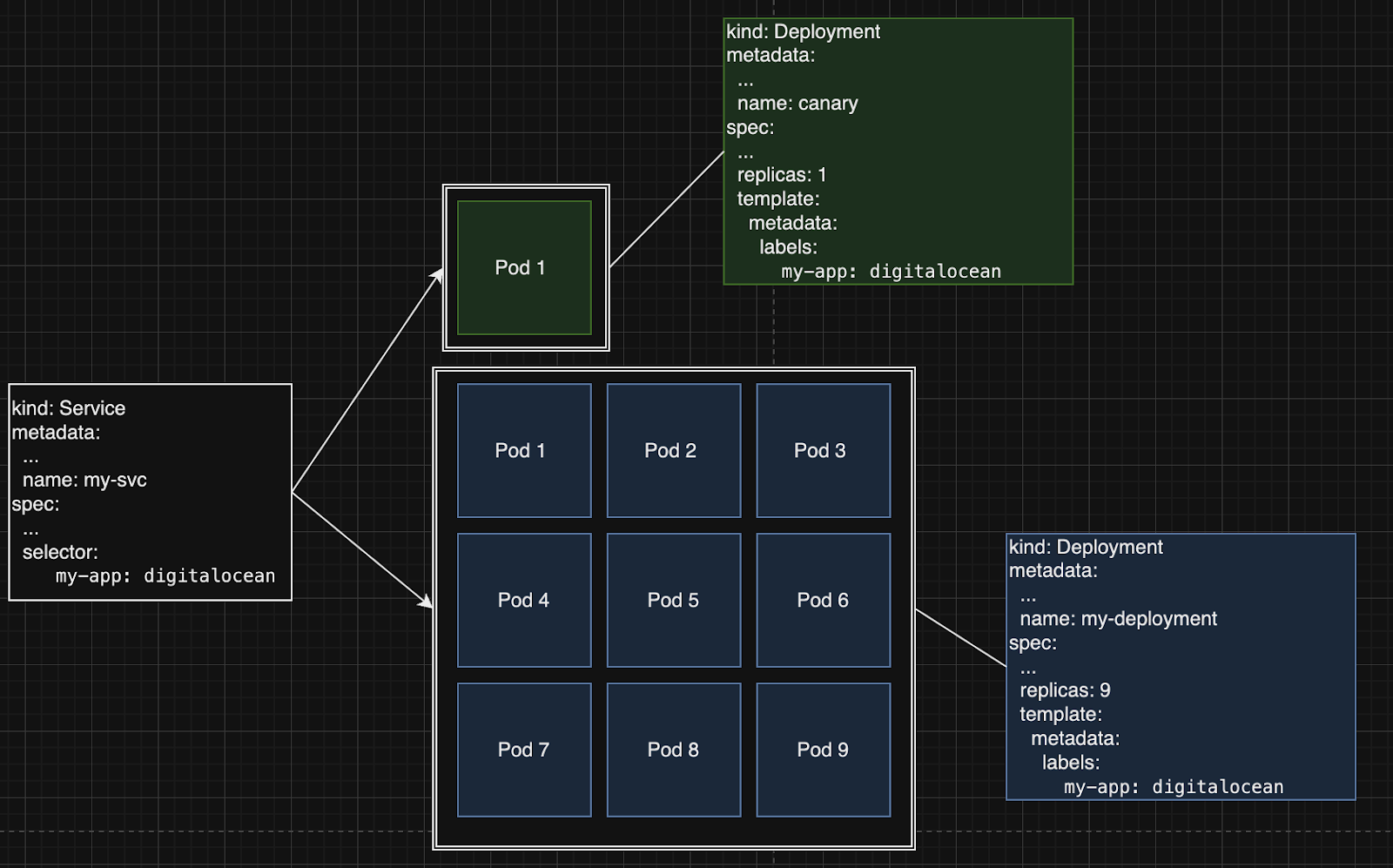
As you can see, the green canary rollout percentage can easily be changed by increasing or decreasing the amount of replicas of the canary deployment. Depending on your application’s needs and the 4 golden signals that you gathered by this deployment initiative, you can determine the actions to take by reverting or pursuing the completion of the new version.
Another rollout strategy that can be easily set up with Kubernetes is the Blue-Green rollout strategy. With this strategy, you’ll introduce a new version by having two separate deployments. One deployment with the new version (Green) while the other contains the current version (Blue).
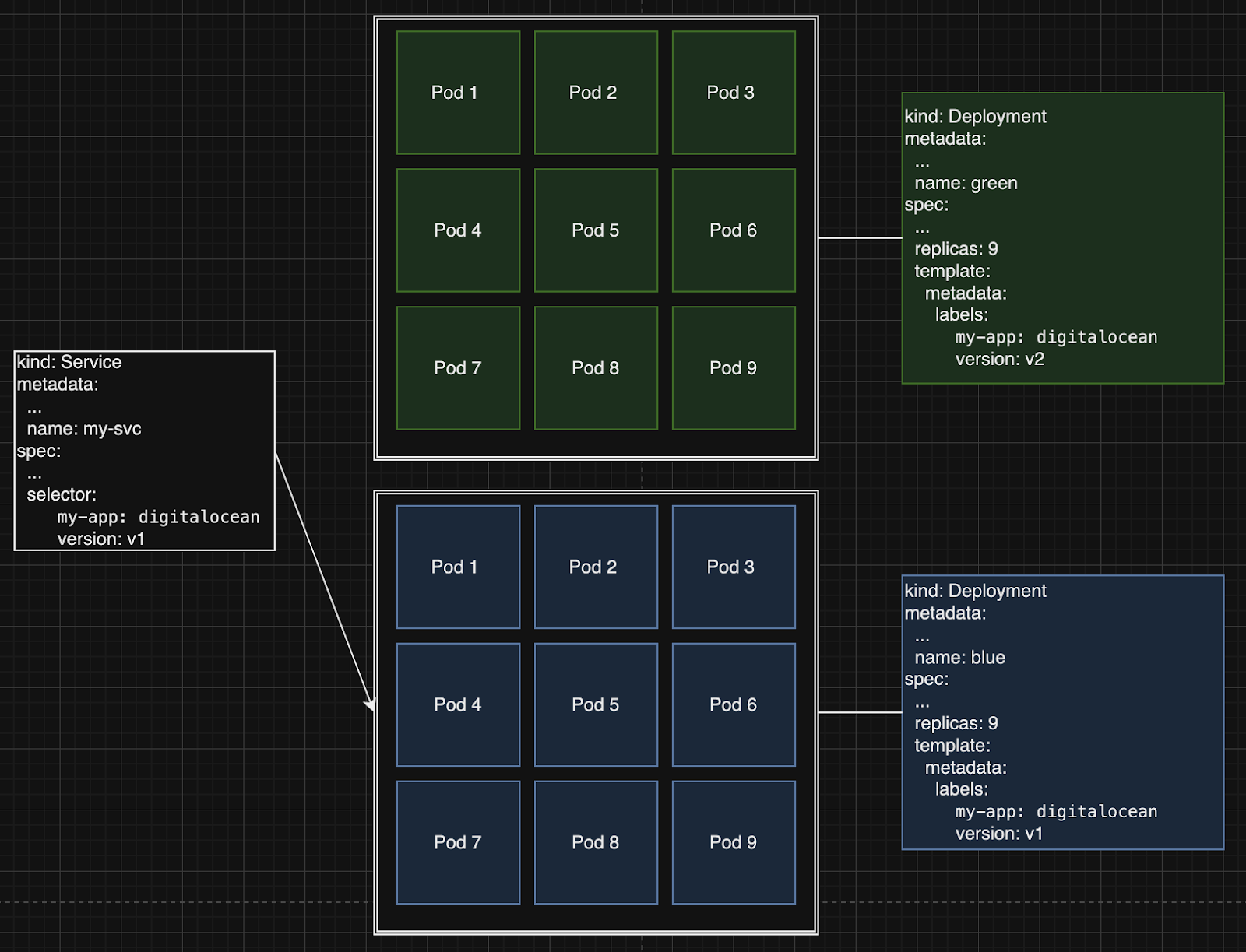
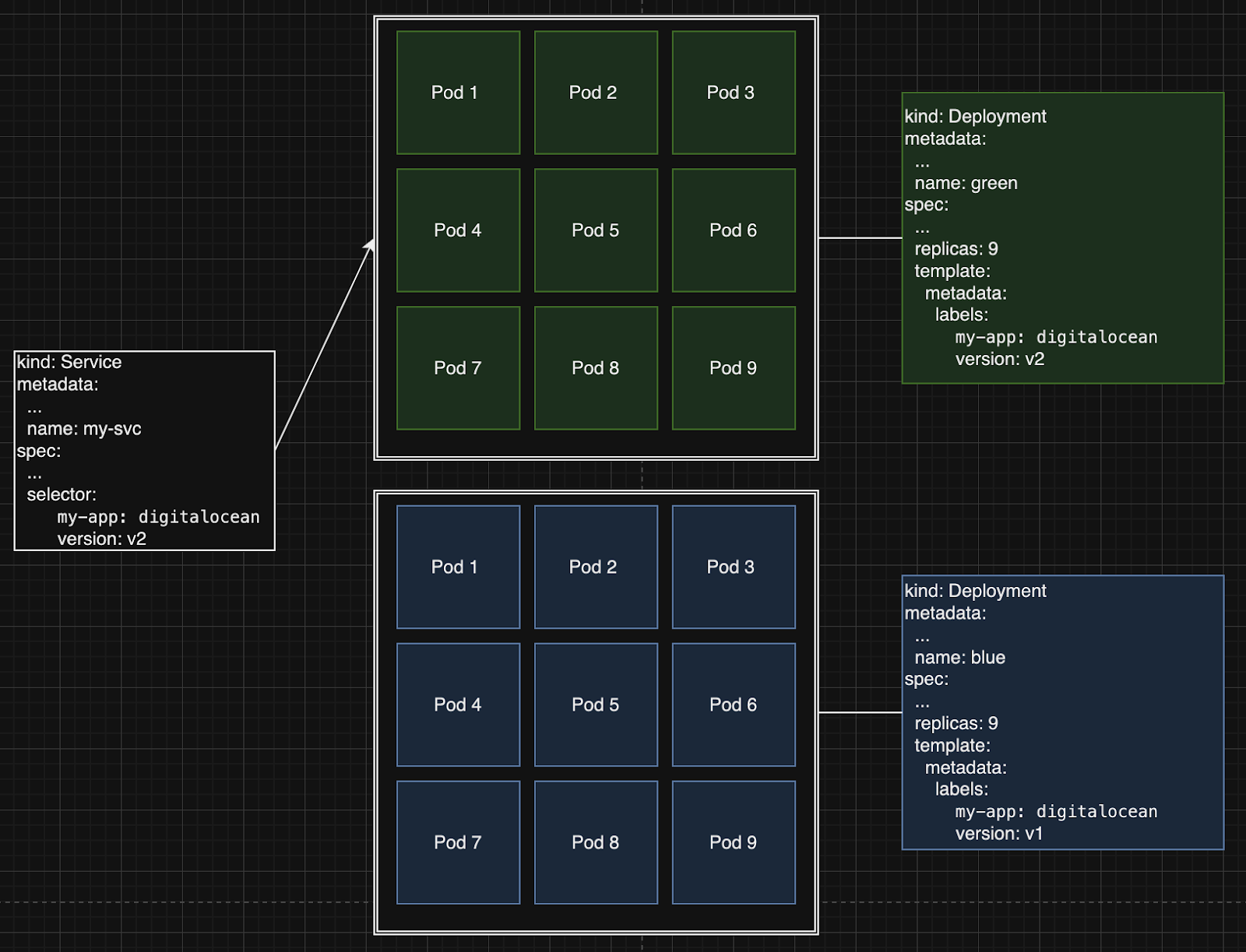
As you can see just by changing the Kubernetes service selector field to match the new v2 version labels, you can redirect the entire traffic to the green deployment v2. Depending on our 4 golden signals metrics you gathered, if our tests are successful, you can drop the blue deployment (old version) and continue with the green deployment (new version). In the event the tests are unsuccessful, can easily revert back to the blue deployment, tear down the green deployment, and review what went wrong from the gathered metrics and logs.
Checklist: Use Pod scheduling (Affinity rules & Pod topology)
In DigitalOcean Kubernetes, your cluster consists of one or multiple worker nodes (Droplets) running your applications. This means that if your application pods are not spread out to one or more worker nodes, they could be impacted by a failure on the worker node itself. Since the DOKS platform supports only the last 3 minor versions, eventually your cluster will have to undergo a cluster upgrade to the last supported DOKS version. This will trigger a rollout of your worker nodes and could cause some reliability issues if you don’t spread your applications throughout multiple nodes. This spread issue could also surface when recycling manually worker nodes or if you are using node autoscaling. This issue can be solved by using pod topology spread constraints. This Kubernetes feature is really powerful since you can control how pods are spread across your cluster’s nodes. If we take an example of a DOKS cluster with 3 worker nodes running a deployment App1 of 4 replicas.You want to avoid the following scenario:

In the above example, all the App1 deployment pods are scheduled on the same worker node. If the Worker node 1 is removed for any of the reasons mentioned above, the application will experience some downtime. Now let’s introduce the topologySpreadConstraints to our deployment resource.
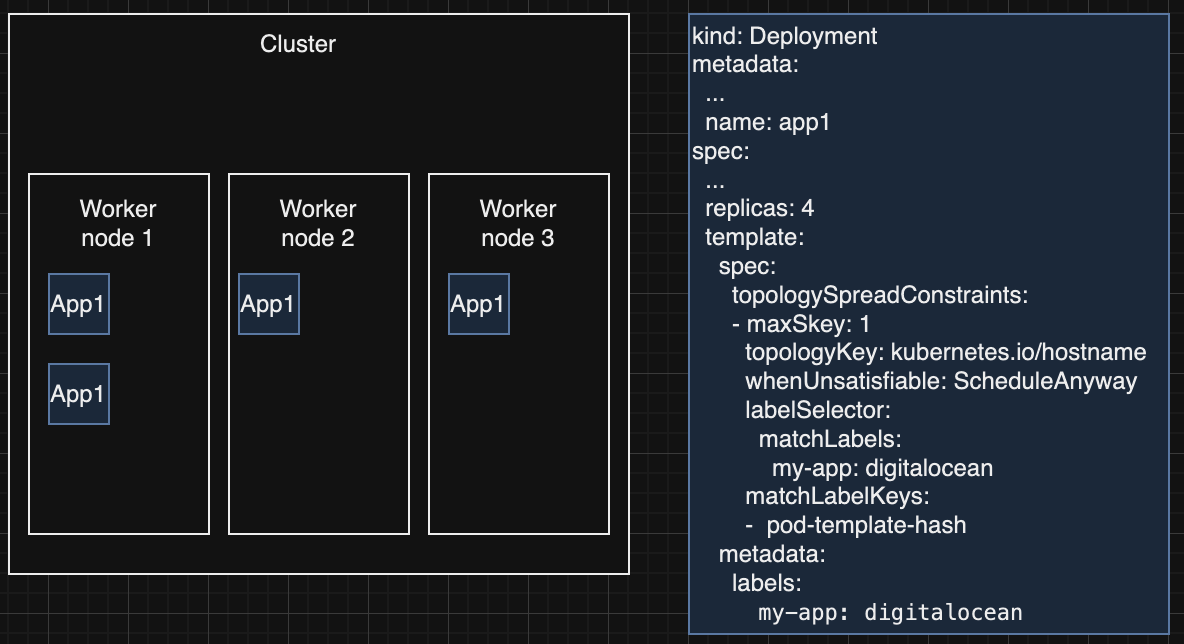
With this new configuration you can now survive a worker node termination without any downtime for the application App1. The above example is just touching the surface of what topology spread constraints allows you to do but if you want more information about the subject and more advanced configuration, you can access the Kubernetes documentation on more advanced topics.
Checklist: Plan for Smooth Upgrades
When planning for a smooth upgrade of DigitalOcean Kubernetes (DOKS), it’s crucial to test your application thoroughly to ensure it remains compatible with rapidly evolving Kubernetes APIs. Understanding the specifics of how DOKS manages upgrades is also essential. DigitalOcean performs surge upgrades by default, which involves creating up to ten additional worker nodes at a time in a pool and then recycling the existing nodes. While this method aims to minimize downtime, it can still disrupt workloads if not managed carefully.
To mitigate potential disruptions during cluster upgrades, which are a common cause for node shutdowns, it’s important to implement graceful shutdown procedures for your pods. For stateful workloads, which require more time to drain from a node, DOKS provides a grace period of up to 30 minutes for node drainage. Additionally, employing a pod disruption budget is recommended to protect stateful workloads during these upgrades. This budget helps ensure that a minimum number of pods remain running during the node replacement process, preserving the integrity and availability of your services.
Checklist: Use unique tags in your images to avoid different versions in containers
When creating a new pod, the default image pull policy in the container specification ensures that the image is pulled only if it doesn’t already exist on the node where the pod is scheduled to run. This can lead to inconsistencies if you reuse the same tag name, such as “latest,” for different builds of your application.
Consider a scenario where you build your code into an image, push it to your container registry using the “latest” tag, and create a deployment using that tag in your DOKS cluster. The first time you deploy your pods, all nodes will pull the image from the registry since they don’t have it cached locally. However, if you update your code, build a new container image, and push it with the same “latest” tag, triggering a new rollout, the pods running on nodes that already had the previous “latest” image will continue running the old code without you noticing. However, any pod on a new node will pull the “latest” image, resulting in an inconsistent application version.
The issue becomes more insidious when you push an image without explicitly specifying a tag. In such cases, the image is implicitly tagged as “latest.” Moreover, even without performing a new rollout, any pod replacement that occurs after the “latest” image is updated will run the most recent version of the image tagged as “latest.”
To prevent these inconsistencies and help ensure that your pods always run the intended version of your application, it is highly recommended to use semantic versioning tags or the commit SHA to uniquely identify each build. This practice helps differentiate between different binaries and configurations, preventing collisions and ensuring that the correct version of your application is deployed consistently across all pods in your cluster.
Summary - Reliability Best Practices
In summary, ensuring the reliability of your applications on DigitalOcean Kubernetes involves implementing best practices across various aspects of your deployment as discussed above. This includes right-sizing your nodes and pods, defining appropriate Quality of Service (QoS) for pods, utilizing probes for health monitoring, employing suitable deployment strategies, optimizing pod scheduling, enhancing upgrade resiliency, and leveraging tags in your container images. By following the checklists and recommendations provided in this guide, you can build reliable and resilient applications that can withstand failures, recover gracefully, and maintain optimal performance in your Kubernetes cluster.
Some vendors specialize in enhancing Kubernetes reliability by proactively identifying and resolving issues, as well as refining troubleshooting processes. Some notable ones are Komodor, Robusta, and Fairwinds.
Next Steps
As we continue to explore the ISV journey of Kubernetes adoption, our ongoing blog series will delve deeper into the resilience, efficiency, and security of your deployments.
-
Scalability (Part 4): Explore how to manage zero-downtime deployments, readiness/liveness probes, application scaling, DNS, and CNI to maintain optimal performance under varying loads.
-
Disaster preparedness (Part 5): Discuss the importance of having a solid disaster recovery plan, including backup strategies, practices and regular drills to help ensure business continuity.
-
Security (Part 6): Delve into securing your Kubernetes environment, covering best practices for network policies, access controls, and securing application workloads.
Each of these topics is crucial for navigating the complexities of Kubernetes, enhancing your infrastructure’s resilience, scalability, and security. Stay tuned for insights to help empower your Kubernetes journey.
Ready to embark on a transformative journey and get the most from Kubernetes on DigitalOcean? Sign up for DigitalOcean Kubernetes here.
Related Articles

How SMBs and startups scale on DigitalOcean Kubernetes: Best Practices Part V - Disaster Recovery
- August 14, 2024
- 7 min read

How to Migrate Production Code to a Monorepo
- August 13, 2024
- 11 min read

Simplifying Distributed App Complexity with App Platform’s Log Forwarding and OpenSearch
- August 8, 2024
- 3 min read